
Anteriormente, en esta serie, vimos Power Query vs Power Pivot – Metadatos y relaciones
Estamos comparando el funcionamiento de Power Query y Power Pivot y hoy nos vamos a centrar en cómo y cuándo se importan los datos.
Extraer datos con Power Query
De la forma que hemos visto antes, conectamos a un servidor SQL Server, seleccionamos una Base de datos y tabla o vista, con el comando Editar o doble clic entramos en el Editor de consultas.
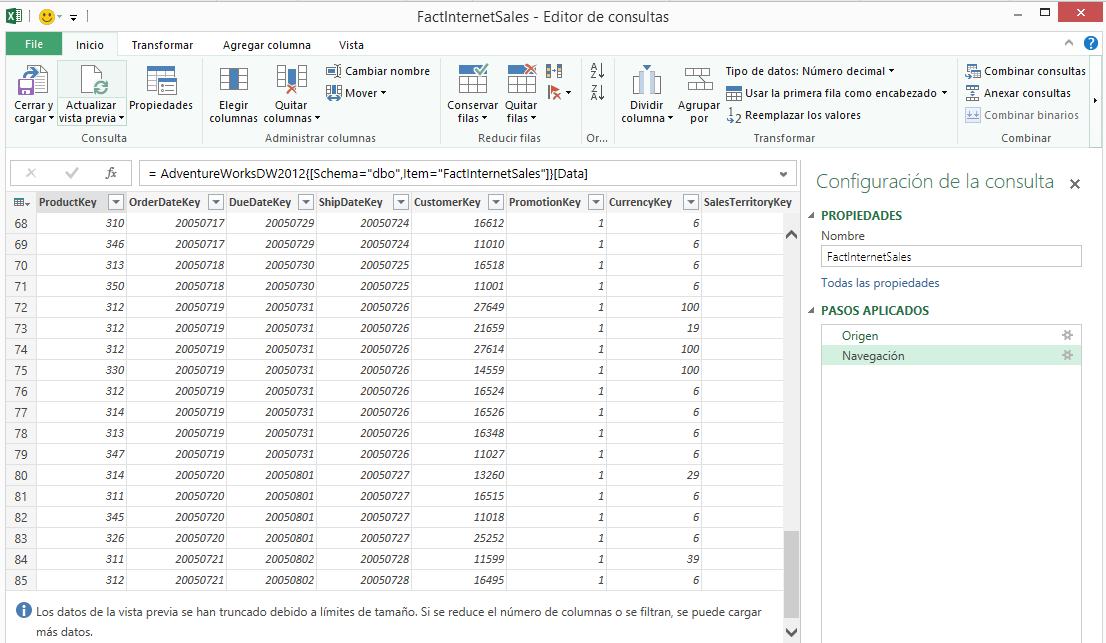
Los datos que vemos son apenas un subconjunto de los que existen en la Base de datos, la idea es ofrecer una presentación preliminar del contenido de la tabla para que podamos realizar los pasos o transformaciones necesarias para crear la consulta que luego se ejecutará en el servidor para descargar los datos a hoja Excel o modelo de datos Power Pivot.
Aparentemente vienen los datos; pero no es así, basta con desplazar la barra lateral para poder ver el mensaje que nos avisa sobre que han sido truncados los datos.
Actualización de datos con Power Query
Cuando trabajamos con Power Query nuestro objetivo es definir la consulta que luego extraerá los datos. Si, mientras estamos trabajando con el editor, ocurren actualizaciones en los datos, se verán reflejados en el momento en que, al salir del editor, con la opción definida para Cerrar y cargar del menú Archivo o File, se ejecute la consulta.
Hasta ahora lo que hemos definido en la consulta es apenas la conexión a la Base de datos y la tabla FactInternetSales. El código M que se ha generado es el siguiente:
let
Origen = Sql.Databases("VM-SQL12"),
AdventureWorksDW2012 = Origen{[Name="AdventureWorksDW2012"]}[Data],
dbo_FactInternetSales =
AdventureWorksDW2012{[Schema="dbo",Item="FactInternetSales"]}[Data]
in
dbo_FactInternetSales
Extraer datos con Power Pivot
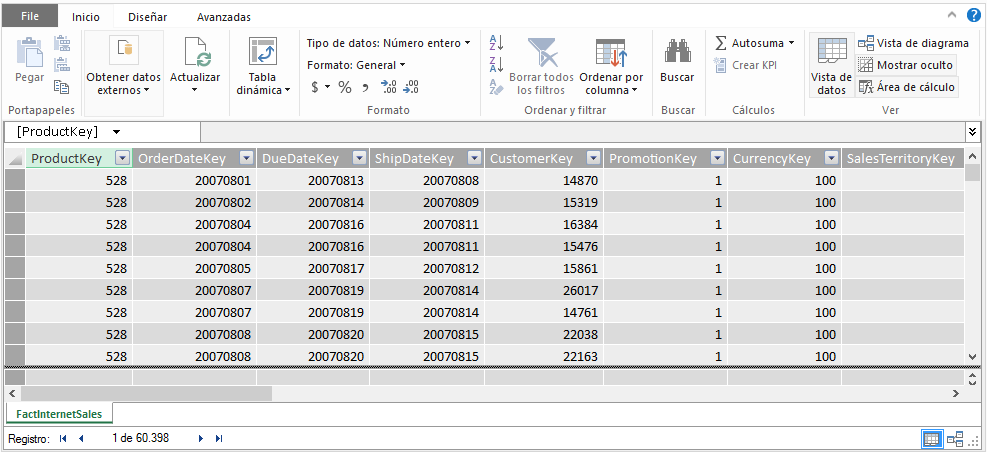
Cuando conectamos desde el modelo de datos a una Base de datos alojada en un servidor SQL Server, y seleccionamos una tabla, Power Pivot trae todos los datos, en este caso los 60.398 y los trae al modelo de datos, a Excel, creando un duplicado de lo que existe en el momento de la extracción.
Actualización de datos con Power Pivot
Si en el origen de datos subyacente, este caso SQL Server se van sucediendo actualizaciones en los datos, Power Pivot no actualiza estos cambios, a menos que actualicemos desde el menú Inicio, grupo Actualizar. En ese caso Power Pivot ejecuta nuevamente la consulta al servidor.
La consulta que se ejecuta desde el motor de Power Pivot al servidor SQL Server, dependerá de lo que se haya definido previamente y se puede ver en la ficha Diseñar, comando Propiedades de tabla.
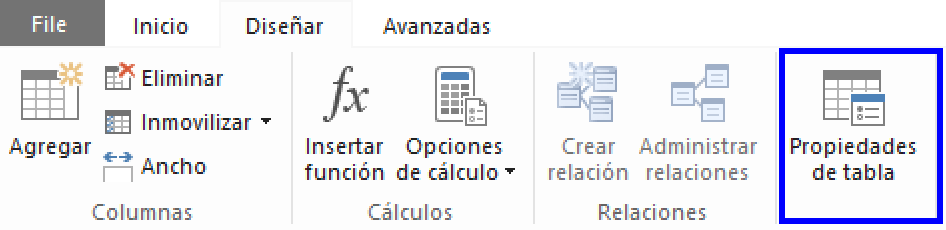
En este caso, como no definimos ningún filtro sobre filas ni sobre columnas tenemos esta instrucción SQL, que es la que se va a ejecutar una y otra vez para actualizar los datos que estén en el servidor.
Es muy importante entender que mientras con Power Query no estamos consumiendo demasiados recursos de memoria, porque apenas trae una muestra de los datos, con Power Pivot nos traemos todo, especialmente si como en nuestro caso no hemos afinado la consulta y estamos haciendo el temido y nada óptimo SELECT *.
Visto esto, me gustaría comentarles la sobre la disponibilidad de elementos que tenemos a la hora de filtrar, porque podríamos cometer errores al no tener la información correcta sobre los datos almacenados en el origen de datos.
Datos disponibles para filtrar con Power Query
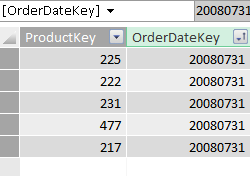
Digamos que necesitamos filtrar por la fecha, por la última fecha que aparece en la columna OrderDateKey, desde el Editor de consultas Power Query nos avisa que la lista puede estar incompleta.
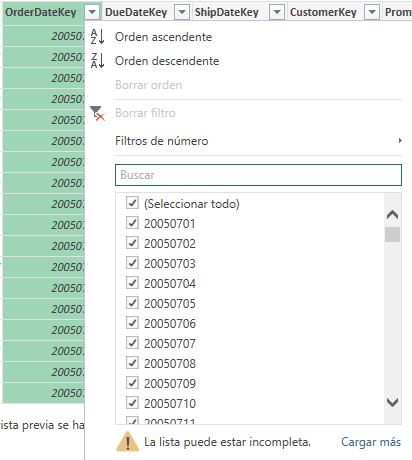
Podemos cargar más, hasta el límite de mil.
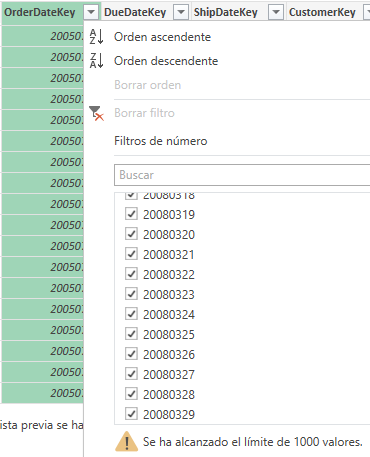
Si ordenamos las fechas de forma descendente, entonces tenemos acceso a esas fechas más recientes.
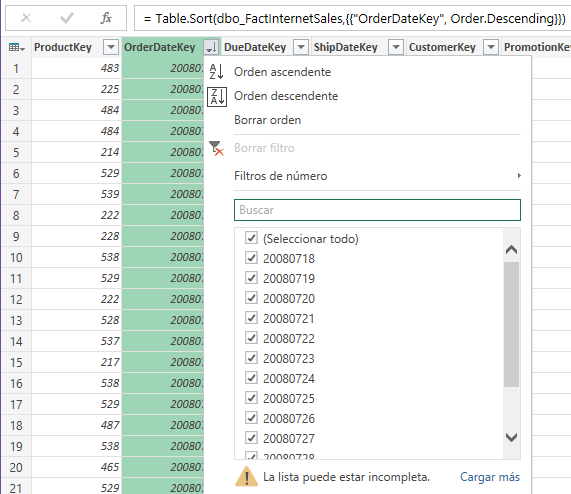
Si cargamos más, nos ofrece más valores, hasta el límite de mil, como antes, quedando fuera del filtrado las fechas más antiguas.
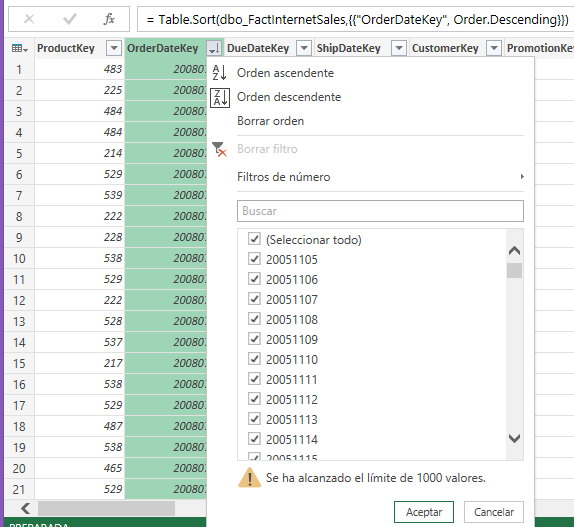
Datos disponibles para filtrar con Power Pivot
Desde el modelo de datos Power Pivot, filtramos por la misma columna OrderDateKey, en este caso el motor nos muestra los primeros mil valores desde la primera vez.
Además, nos deja un enlace a la ayuda de Power Pivot dentro de la ayuda de Excel
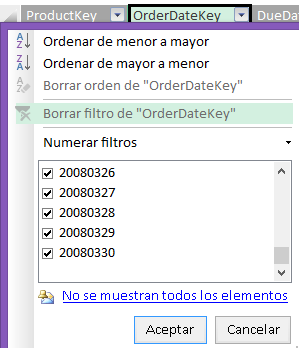
Aunque ordenemos los datos, entre los datos preliminares no tenemos opciones de filtrado para los valores más recientes de fecha, los vemos que aparecen en la columna de la tabla, porque en la tabla como tal están todos los datos; pero no es posible filtrar por ellos desde la lista de valores disponibles.
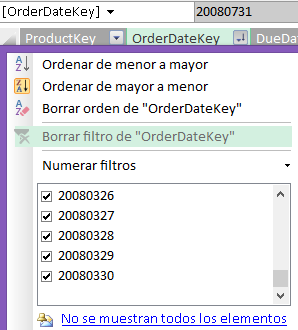
Es decir, si necesitamos filtrar por una de las fechas más recientes, que no están disponibles, tenemos que utilizar la opción Numerar filtros, un ejemplo:
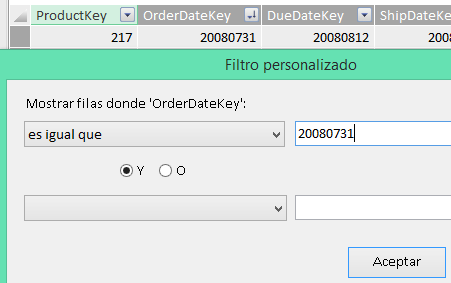
Con ambas herramientas, Power Query y Power Pivot, podremos importar, examinar la vista previa de los datos y filtrar, aunque cada una de ellas con sus funcionalidades específicas. En la próxima entrada veremos algunos aspectos de la transformación de los datos.
No te pierdas el resto de entradas de la serie Power Query vs Power Pivot

Buenas tardes Ana.
Ante todo, enhorabuena por tu web, tu post me ha servido muchisimo de ayuda, ahora mismo estoy trabajando en un proyecto en el que me viene de perlas toda esta info, pero me ha surgido una dudilla…tengo un modelo PowerPivot conectado a una base de datos SQL Server, y lo muestro en un Sharepoint 2013 a través de Excel Services, y mi pregunta es, hay algún modo de que al actualizar la base de datos (ETL o inserts), el modelo de PowerPivot se autorefresque sobre Sharepoint? Del mismo modo que podría actualizar cualquier Informe hecho con SSRS. Un saludo!
Me gustaMe gusta
Hola Marco
Gracias por tu mensaje y amables comentarios.
Siento el retraso, estoy intentando ponerme al día con la web.
Por todo lo que he demorado seguramente ya has visto, que el modelo dentro de Power Pivot lo que almacena es una instantánea de los datos externos obtenidos y que toca refrescarlos.
Quizás una idea podía ser trabajarlos desde un proyecto de VS SSAS tabular y que puedas procesar la base de datos tabular, como parte del agente SQL Server o con un script XMLA que ejecutes, después de actualizar la Base de datos relacional SQL Server.
Espero que ya ido muy bien en ese proyecto.
Saludos,
Ana
Me gustaMe gusta